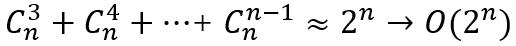Introduction To Operation Research
实习部门做的问题主要是供应链方向的优化,包括库存控制、排产调度、装箱装柜、物流优化等等,对于建立好的数学模型,现阶段使用的Solver是GUROBI,小组成员对于其中求解的原理较感兴趣(不至于完全将其当成黑箱使用),介于我是小组中唯一的OR方向(大部分是CS、统计方向),leader希望我对这一块做个详细的调研,并与某天做一次presentation。
为了形成体系化的讲解,对单纯形部分的理论知识进行了补充,结合16年暑假跟随华南理工的一位教授学习的MIP solver知识,用一些图将自己的理解形象的表示出来。最后展示效果不错,因此也在这里进行记录与分享。
展示内容包含一些我自身对知识的理解,如有错误,请随时提出。
内容知识涉及的参考文献、资料,都可以在我的github中documents项目中查询到。
内容
1.目录
介绍的内容包括六方面:1.线性规划;2.单纯形法;3.Column Generation;4.Bender Decomposition;5.MIP Solver Core;6.GUROBI
2.线性规划
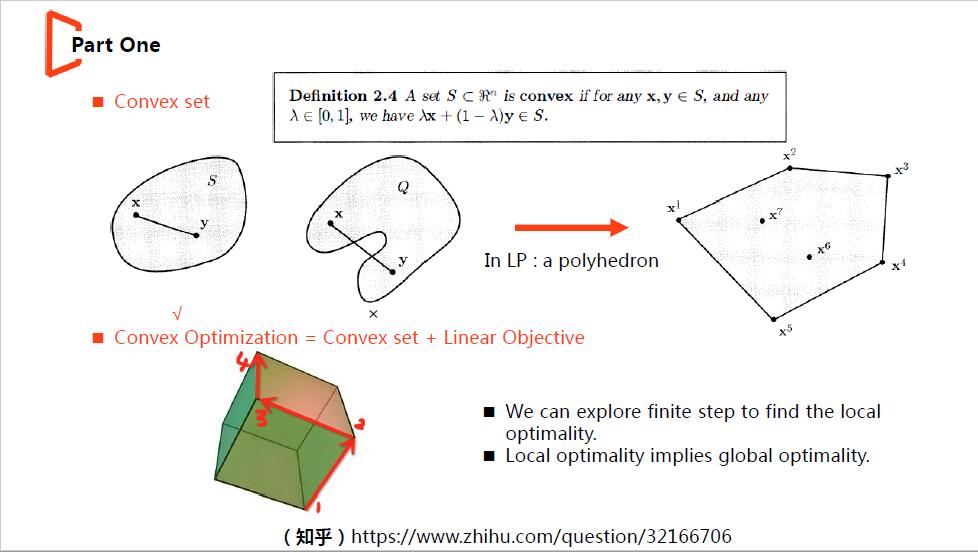
线性规划是凸优化的一种,先来看看凸集与凸优化的定义。
凸集:集合中任意两点连线上的点仍属于该集合,否则为非凸;线性规划的解空间因为是由一个个超平面切分空间得来,故解空间是一个规则的多面体(边缘线性的凸集)。
凸优化:解空间为凸集,且目标函数为线性的优化。
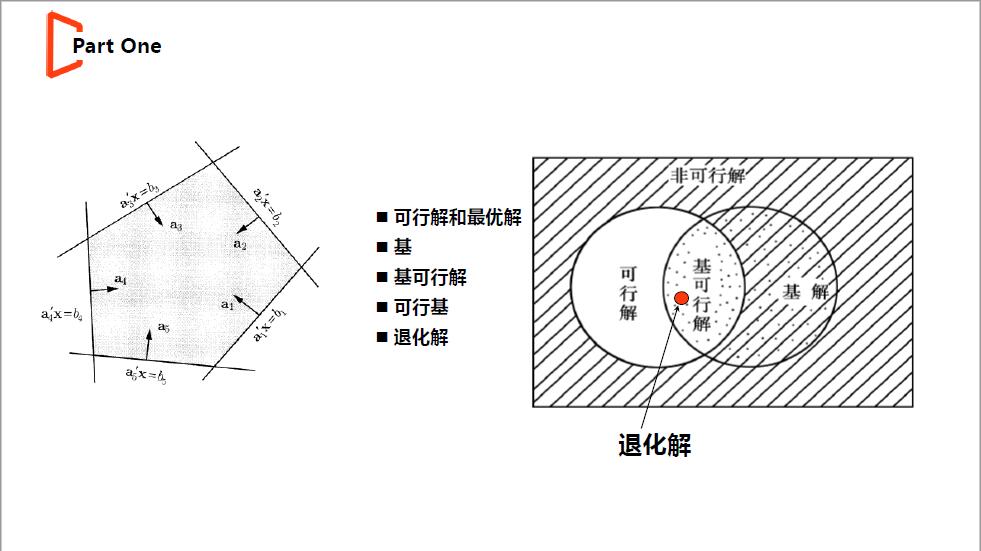
凸优化有两条很重要的性质,为单纯形的实现做了铺垫:a.从任意点出发,我们可以在有限步内移动到局部最优点;b.局部最优点即是全局最优点。再补充一些运筹学中的基本定义:a.所有的问题都可以转化为标准式;b.系数矩阵A(m*n)满秩,则任意线性无关的m列向量成为基B,对应的变量为基变量Xb,余下的列(n\m)构成非基N,对应的变量为非基变量Xn;c.满足所有约束条件的解为可行解,至少违背一条约束的解为非可行解。更多详细的定义可借一本运筹学中文教材参考。
3.Simplex Method
凸优化的性质给单纯性法提供了理论基础,这里给一个通俗的解释:线性规划问题的解空间是规则多面体,单纯形法沿着多面体的边移动,每次移动都向着使得目标更优的方向,则有限步内一定可到达局部最优点(全局最优点)。下面的几张slides是关于单纯形法的具体实现与理论证明:
这一部分内容主要参考教材《Introduction to linear programming》2-3章,这里阐述一些通俗的解释:
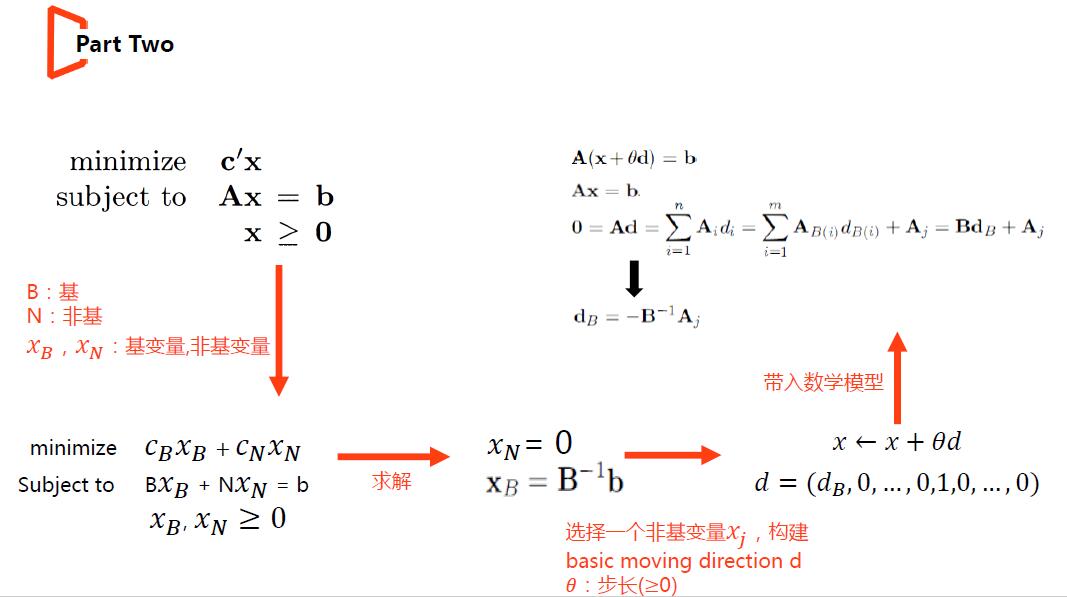
(1)单纯形法沿着多面体的边移动进行优化,每一条边都表示针对当前点的可移动方向。
(2)在移动时要保证使得目标更优,但移动过程中,不能违背任一约束条件(保证解依旧在可行域之中),解在沿着多面体的边移动时,当前基变量中的一部分会随着移动而不断减小,当存在一个基变量减小为0时,必须停止移动(继续移动会违背变量大于等于0的约束),此时到达多面体的一个新节点,新加入的变量值大于0,原先的一个变量(不考虑退化情况)值减小为0,这就是单纯形法的换基过程(可参考slide-3中的实例)。
(3)通过slide中的推导会发现,我们在线性规划中总是提到的reduced cost就是目标值增量,因此在最小化问题中,希望沿着增量小于0的方向移动;一旦发现某一顶点可移动边的所有增量(reduced cost)都不小于0,则求得最有解,这就是对单纯形法中optimality condition的解释。
(4)slide-5对单纯形算法的流程做了描述(based on minimal problem),step1是为算法确定初始解,这一步其实很影响算法效率(在保证搜索开始的点,初始解为基可行解的同时,若其已离optimal很近,效率不高才怪);step2计算reduced cost,选择reduced cost小于0的方向移动,存在多个rd小于0的方向时,选择策略灵活(reduced cost最小表示沿着该方向移动单位步长,会使得目标降低的更快,故有些教材会建议选取rd最小的方向移动的策略,但reduced cost越小,不代表可移动步长也大,所以才说策略灵活);step4则是计算沿着优化方向的最大可移动步长,判别依据是移动中所有变量不能小于0。4.大规模LP求解
在问题规模上升到移动一定程度后,很多算法的求解效率大幅度降低,此时就会有一大批学者涌入,研究算法如何适配大规模问题,这之中一个很重要的思想就是分解。我们再次考虑LP的模型,明显可知问题规模的增大主要来之两方面:a.变量数目增加;b.约束个数增加,列生成(Column Generation)与切平面(Cutting Plane or Bender Decomposition)就是为解决他们而发明出的。
这两个算法单独说理论都要讲好久,故讲解时不谈公式(了解理论前,对单纯形法的推导了解必不可少!),依旧是希望通过通俗的语言来了解它们。抛砖引玉,先给出一张自我总结图:
Column Generation
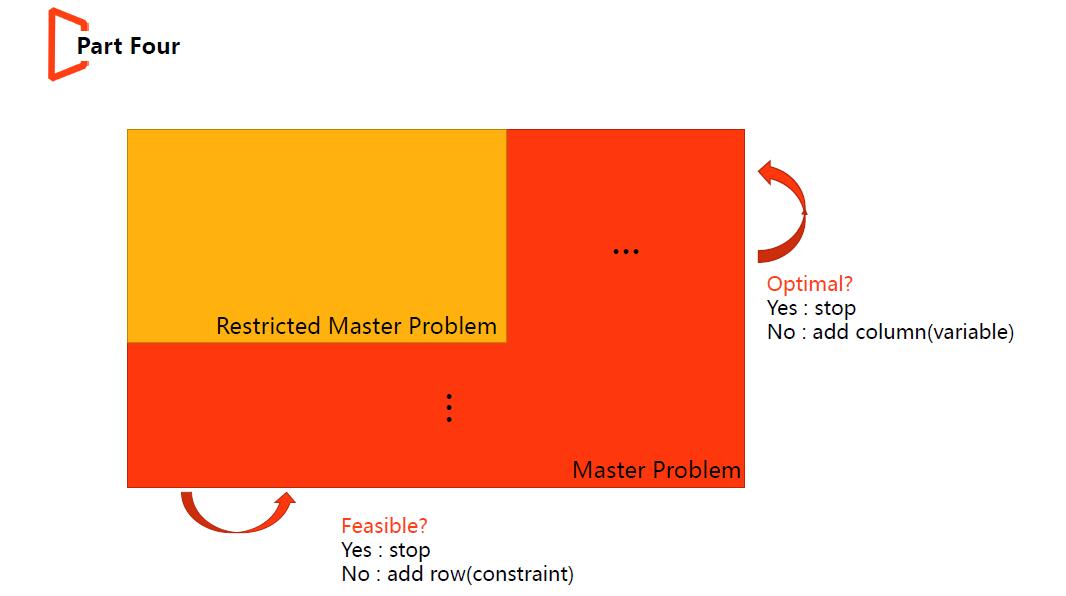
变量较多时单纯形算法的求解效率明显降低,但存在一些问题就是这么BT,如slide中的cut stock problem,当数学模型建成set cover model时,变量的个数为指数级别。考虑到这类问题约束较少,即约束中行个数m远小于列数n,故求解中,可真对原问题(Master Problem)只取很少一部分变量n1(m < n1 << n)做单纯形求解(Solve Restricted MP),但在检验optimality condition时,回到原问题,考虑所有n个变量。
以最小化问题为例,判断解是否最优的条件为检测所有n个变量的reduced cost是否都不小于0,故此时可构建搜索最小化reduced cost的优化问题(sub-problem),根据rd的计算公式形式可知,sub-problem是一个1D-Knapsack Problem,求解效率较高。当sub-problem的最优值 >= 0,则说明n个变量中reduced cost的最小值都比0大,此时原问题依据单纯形法的最优判断条件,达到最优;若sub-problem的最优值 < 0,说明存在需要继续进基的非基变量,问题求解过程继续。
CG拓展:
(1)求解RMP时,可将其转换为对偶问题(虽然RMP相对于MP来说变量数少了很多,但依旧很多,而有证明指出单纯形法求解多约束少变量问题的效率大于多变量少约束问题),对偶问题的解称为单纯形乘子,作为求解sub-prolem目标中的价值系数。
(2)MP的变量被分为考虑集N1,非考虑集N2(N2=N\N1),对于检测出来的N2中reduced cost小于0的变量,需进基,但也可设计一定策略,检测N1中不会再进基的非基变量,将其挪到非考虑集N2中,以此预防N1不断增大,求解RMP效率降低的情况发生。
(3)每次求解子问题时,可让solver给出几个可行解,对应于一次挪动(从N2到N1)的变量个数大于1,加速收敛过程。
(4)……Bender Decomposition
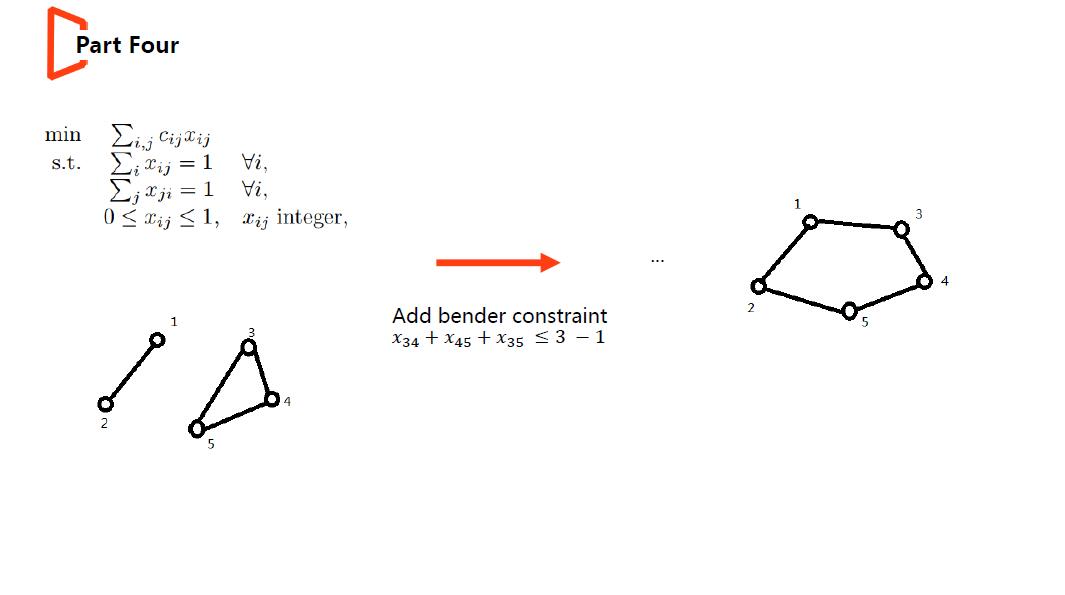
约束较多的问题,常见的组合优化问题TSP就是一个。考虑slide中TSP的数学模型,需存在破子环的约束,该类约束的数量级为指数级,证明如下:
故此时可考虑一开始仅纳入一部分约束进行求解(Solve Restricted MP),在检查解的合法性时则带入所有的约束中检查,将候补集中违背的约束加入RMP,如此反复,直到RMP的最优解满足所有约束,则此时sol* of MP = sol* of RMP。
BD拓展:
(1)被纳入候选集中的约束应满足约束力较弱,对解的结构会造成影响,但对目标值的影响不明显(若明显影响目标,将其不考虑到RMP内时,RMP的解大概率会违背该约束);TSP中的破子环约束就类似,存在子环的解与不存在的解中边的个数一样,其明显影响解的结构,对目标值影响不明显。
(2)上述TSP模型中,候选集的约束来源于定义,实际求解过程中候选集可被不断更新,根据一定数学转换来形成加入RMP的约束,加速收敛速度,这一块在求解MIP的策略中使用较多,称为cutting plane。
(3)BD的思路与CG相似,因本身也是原问题与对偶问题的转换所带来的求解方式的改变,具体的细节可补充下运筹学对偶问题,做更深入的探究。
(4)……小结
算法的核心思想————分解(通过将求解一次大规模问题分解为求解若干个小问题的整合)
5.MIP Solver Core
上述提到的单纯形法适合解LP问题,但实际中很多问题的变量类型是整形的(IP,Integer Programming)或是混合类型(整形实形都存在,Mixed Integer Programming),求解该类问题的框架是怎样的呢?现存最优化求解器(GUROBI、CPLEX、LpSolve等)都支持直接将MIP模型输入,帮助求解,其内部核心的求解框架本章节会简要介绍一下。
求解步骤
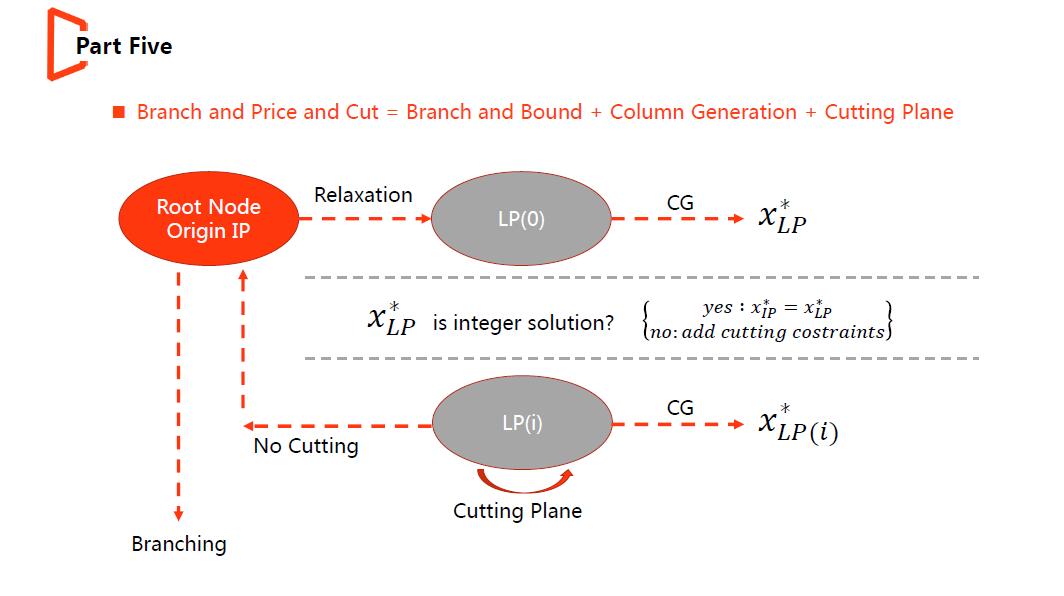
上述两张图是我自己的总结,其核心方法是分支定界法(BB,Branch and Bound),当问题规模较大时,就会在BB中嵌入CG或者Cutting Plane等算法,嵌入CG后成为分支定价法(BP,Branch and Price,再嵌入Cutting Plane后称为Branch and Price and Cut)。
大致求解步骤:
(1)对于一个IP问题,第一步做松弛(Relaxation,将决策变量必须为整形的约束放松为实数形)得到LP问题。
(2)用单纯形法求解LP问题得到solLp*(global optimal solution of LP),当问题规模较大时,单纯形外层套上Column Generation框架。
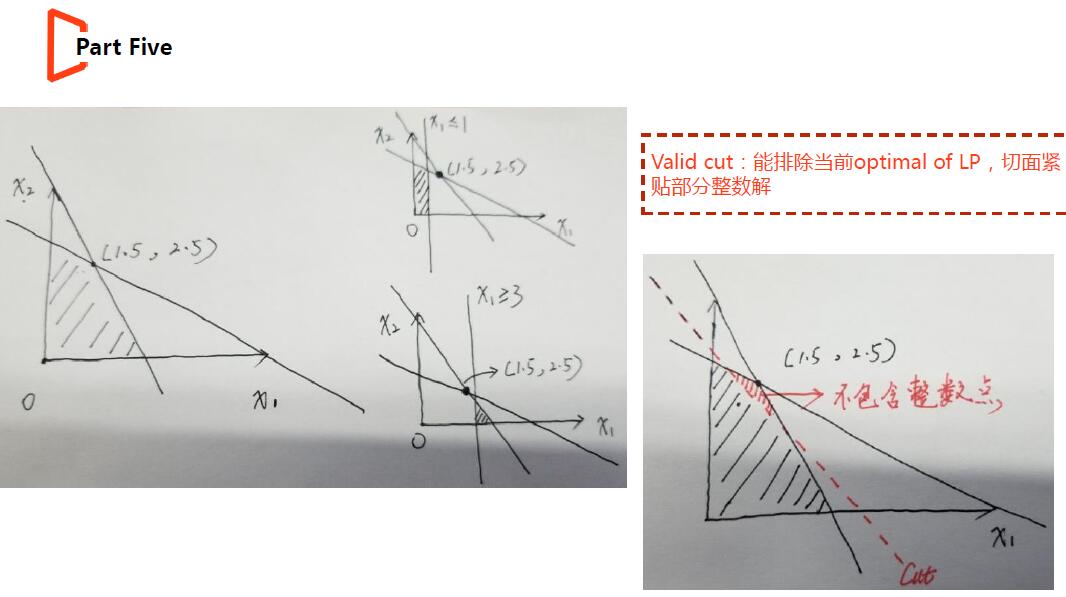
(3)判断solLp*中所有决策变量的值是否是整形,若为是,则该IP问题的解已被找到,有solIp* = solLp*(因为LP是IP的松弛问题,其最优解一定不会比原问题差);若为否,则可考虑是否存在有效的cut(一条cut可看作为问题加上一条约束,切割解空间中的实数解空间,帮助LP的解尽可能与IP等价),每次加cut,都要重复求解LP并做判断工作。当解仍达不到全为整数且不存在有效的cut时,进入步骤4。
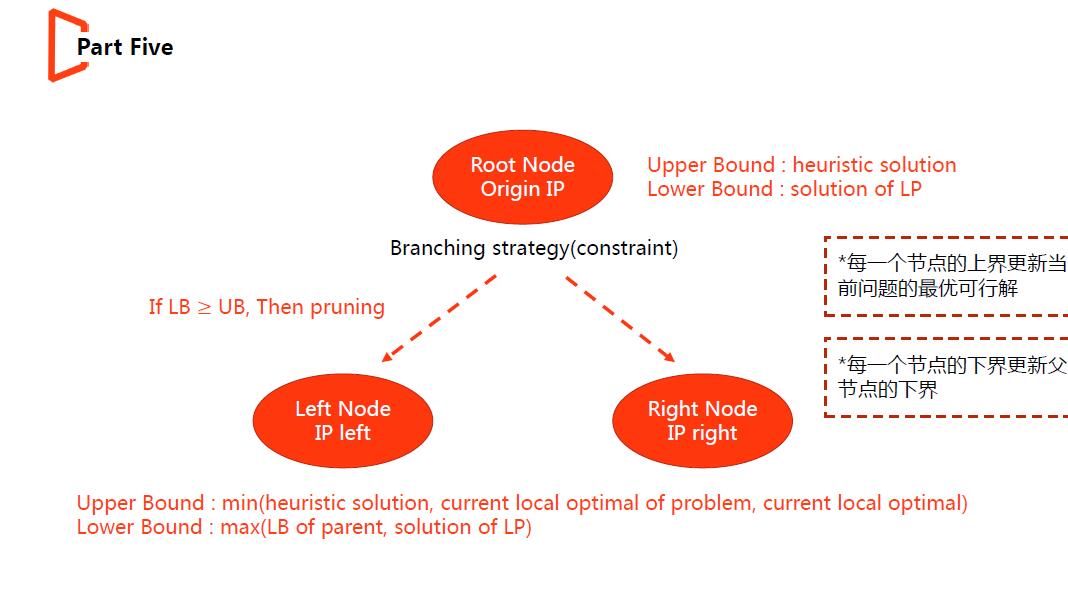
(4)此时回到分支定界的范围,为问题添加分支,将其划分成两个子节点(这里分支可以看作两条对立的约束,将解空间还分成两部分,如LP问题中某个决策变量x = 10.5,则分支约束可为x <= 10及x >= 11,原问题模型分别加上两个约束,形成两个子问题,即子节点)。
(5)子节点重复步骤1-3,但需不断更新自身的Bound,包括UB(Upper Bound)及LB(Lower Bound),这两者为问题的最优解限制了一个范围,即LB <= sol* <= UB;节点的UB一般是整个问题目前为止搜索到的最好的可行解(全部变量为整形),也可以是用启发式算法求得的可行解,无论什么方式,取最小;LB一般是松弛问题LP的解,也可以是其他方式,取最大值。对于某一节点,若UB < LB时,则无继续搜索的必要,进行剪枝操作,若LB = UB则当前节点已经搜索完毕,得到可行解,用其更新整棵树(Branch and Bound可以看成树搜素过程)的UB,若LB < UB,则进行步骤1-4的工作。
(6)当整棵树搜索完全时,即可得到global optimal of IP。
求解效率关键点分析
(1)分支策略的选择对求解效率影响较大,每次分支期望能平均划分解空间,这种思想类似于二分排序。
(2)好的cut(求出实数空间的同时,尽量保证约束所在的超平面覆盖整数解,因为单纯形法是沿着边进行搜索的)能保证LP的解尽可能接近IP,减少分支过程,加速求解。
(3)分支定界法的原型仍然是树搜索,那么节点的搜索顺序很重要,好的顺序能优先搜到较好的区域,得到较好的UB,加速剪枝过程,提高效率。
(4)每一个节点的bound确定方式较多,可根据问题特点特殊设计,加速收敛。
(5)……小结
为求得最优解,算法还是要考虑遍历所有的解空间,剪枝过程筛掉了其中不好的一部分,故整个框架加速了问题求解效率。现OR领域很多论文是自己实现分支定界框架,仅让优化器辅助LP问题的求解,而其创新点就是刚刚说明的影响求解效率关键点的设计;近几年兴起的Machine Learning结合OR的突破点也主要是融入这几步,这段时间也开始在做调研,后期的总结会再形成一篇博文。
6.GUROBI
GUROBI算是现阶段求解效率最高的最优化求解器,实习部门对其进行了采购,学习起来十分简单,官网上都有参考案例。
一旦建立好数学模型,coding过程就是一条条的将变量、目标、约束加入模型中,再运行solve()函数;当然,求解器也有很多进阶功能,如callback、multi-objective等,这些都有消息的参考文件,但一般情况下不会用到。